# first, we predict PM from all the predictors
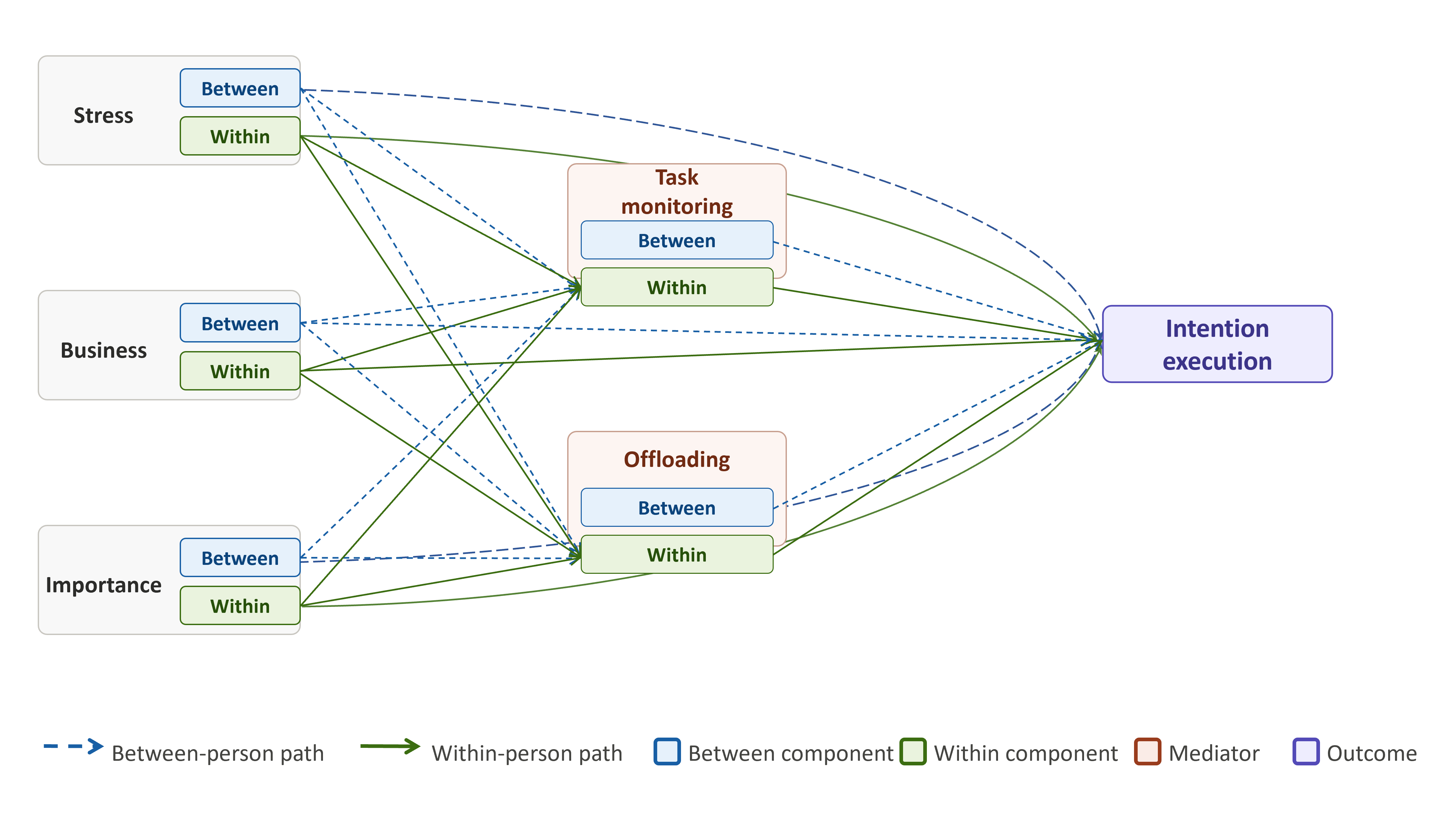
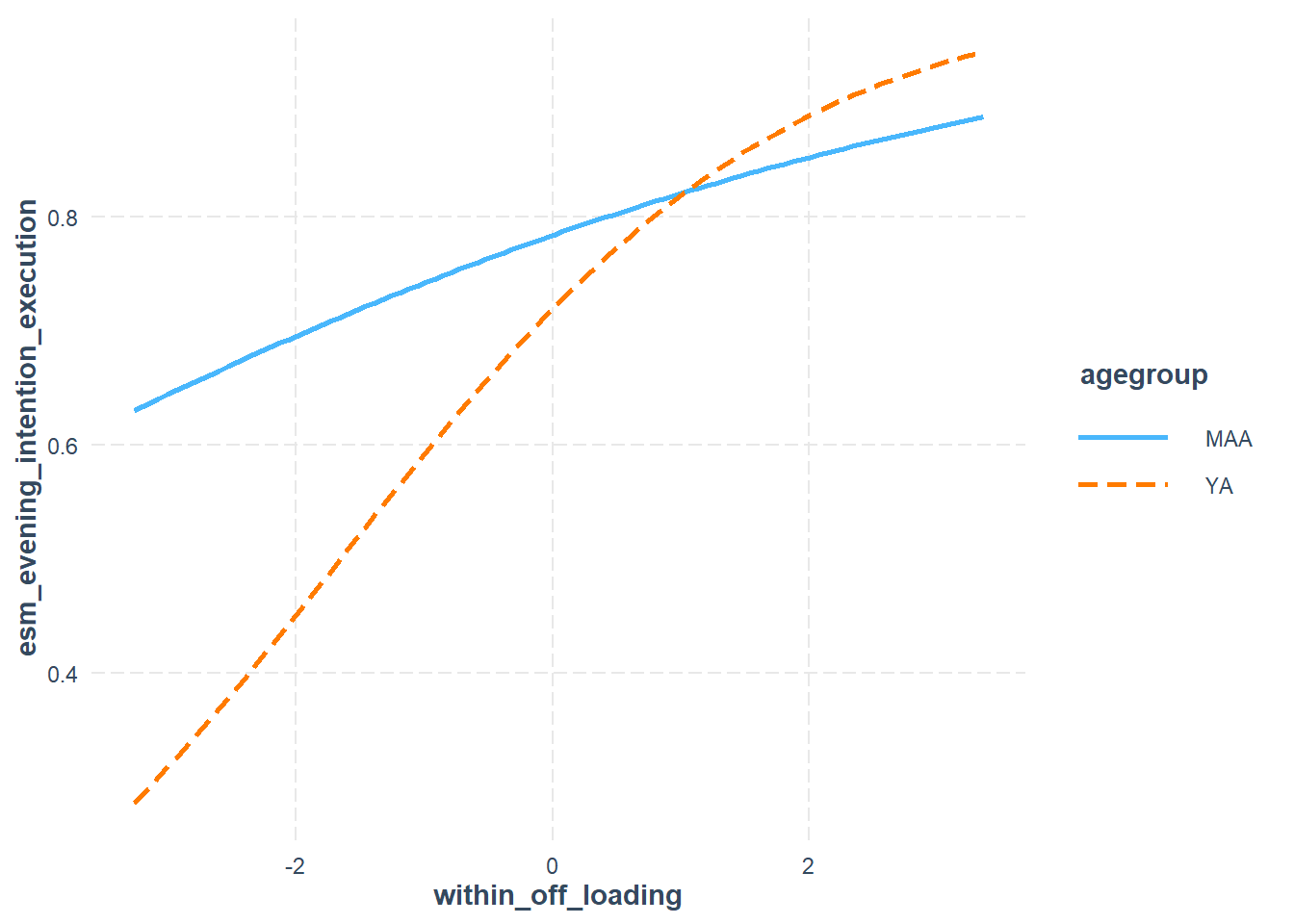
PM_model <-bf(esm_evening_intention_execution ~ # fixed effects
within_stress*agegroup.c +
within_importance*agegroup.c +
within_task_monitoring*agegroup.c +
within_off_loading*agegroup.c +
within_business*agegroup.c+
between_stress*agegroup.c +
between_task_monitoring*agegroup.c +
between_off_loading*agegroup.c +
between_importance*agegroup.c+
between_business*agegroup.c+day.c+
(1 + within_stress +
within_business+
within_importance +
within_task_monitoring +
within_off_loading || ID), # random intercepts and slopes
family = bernoulli()) # we have a binary outcome
# predicting monitoring from stress and importance
monitoring_model<- bf(esm_day_task_monitoring ~
within_stress*agegroup.c +
within_importance*agegroup.c +
within_business*agegroup.c+
between_stress*agegroup.c+
between_importance*agegroup.c+
between_business+day.c+
(1+within_stress+
within_business+
within_importance+
day.c||ID),
family = bernoulli()) # mixture
# predicing off_loading from stress and imortance
offloading_model<-bf(esm_evening_off_loading_r ~
within_stress*agegroup.c +
within_importance*agegroup.c+
within_business*agegroup.c+
between_stress*agegroup.c+
between_importance*agegroup.c+
between_business*agegroup.c+ day.c+
(1+within_stress+
within_importance+
within_business+
day.c||ID), family = bernoulli() )#
# set weakly informative priors
priors <- c(
# Fixed effects: assume standardized predictors
prior(normal(0, 0.5), class = "b", resp = "esmeveningintentionexecution"),
prior(normal(0, 0.5), class = "b", resp = "esmdaytaskmonitoring"),
prior(normal(0, 0.5), class = "b", resp = "esmeveningoffloadingr")
# all the rest is left as defauls
#
# # SD of random effects (hierarchical structure)
# prior( student_t(3, 0, 2.5) , class = "sd", resp = "esmeveningintentionexecution"),
# prior(student_t(3, 0, 2.5) , class = "sd", resp = "esmdaytaskmonitoring"),
# prior(student_t(3, 0, 2.5), class = "sd", resp = "esmeveningoffloadingr"),
# #
# # Correlation priors among random effects
# # prior(lkj(2), class = "cor"), # same across responses
#
# # Residual SDs for continuous outcomes
# prior(exponential(1), class = "sigma", resp = "esmdaytaskmonitoring"),
# prior(exponential(1), class = "sigma", resp = "esmeveningoffloadingr")
)
# fit the model
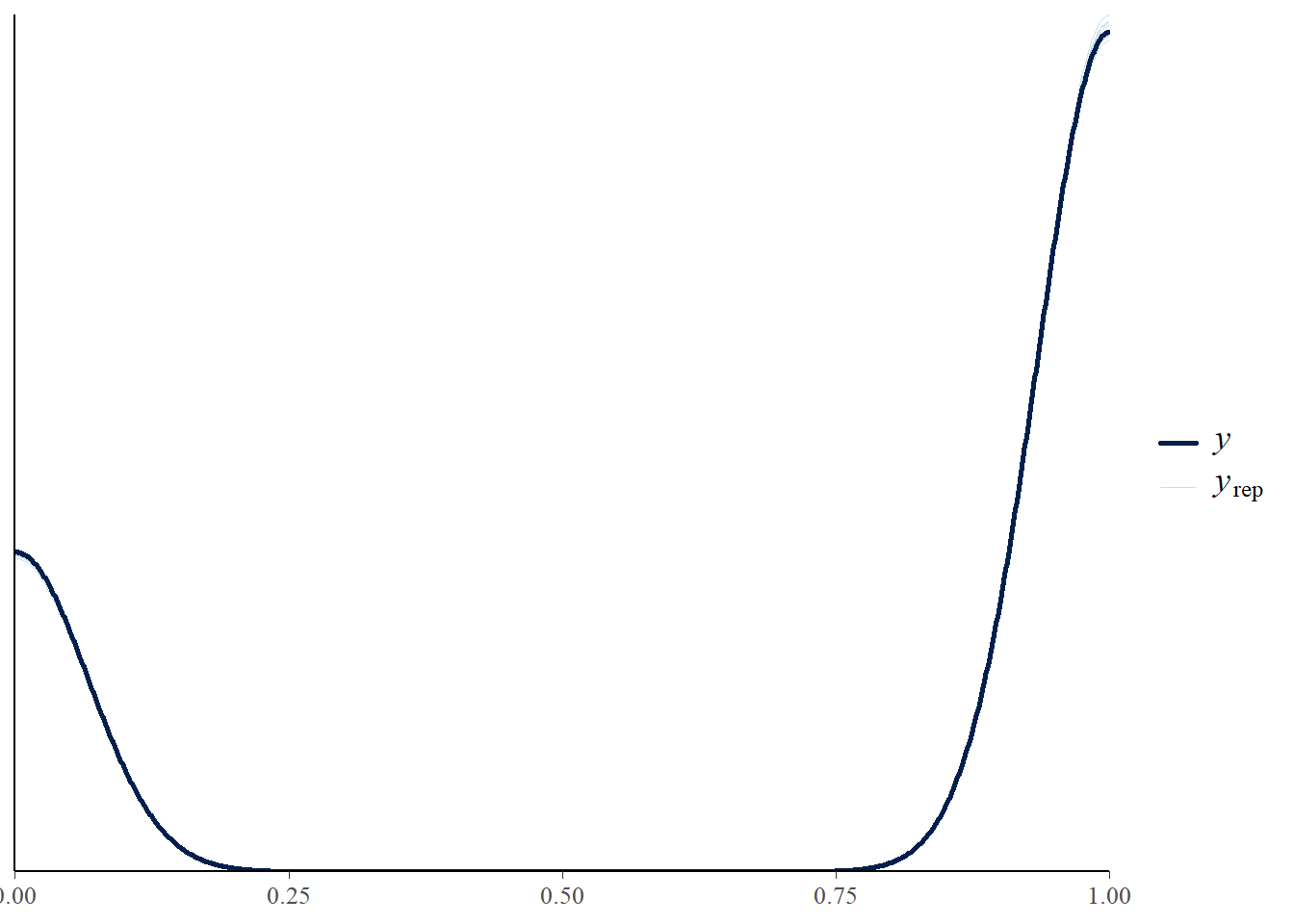
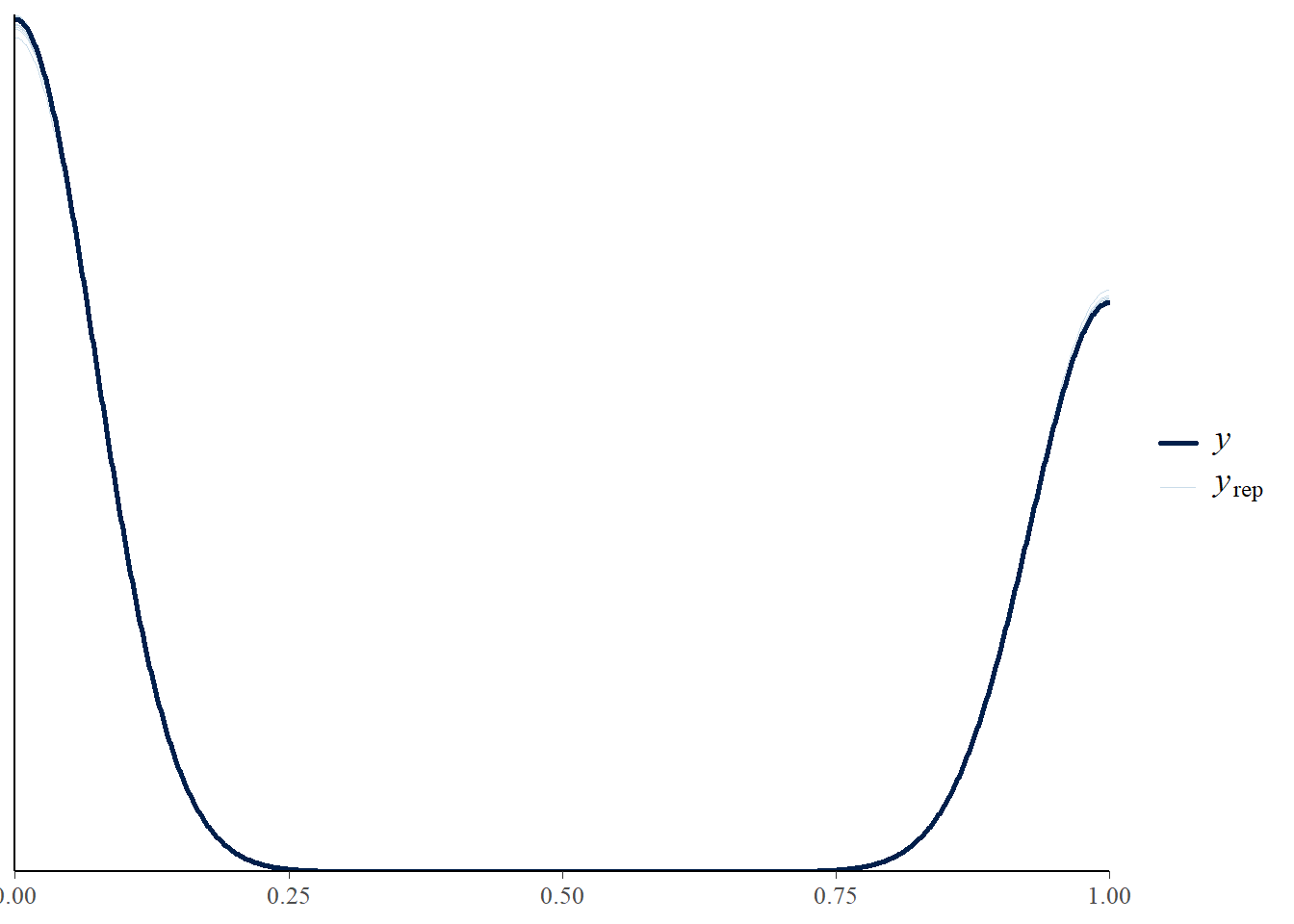
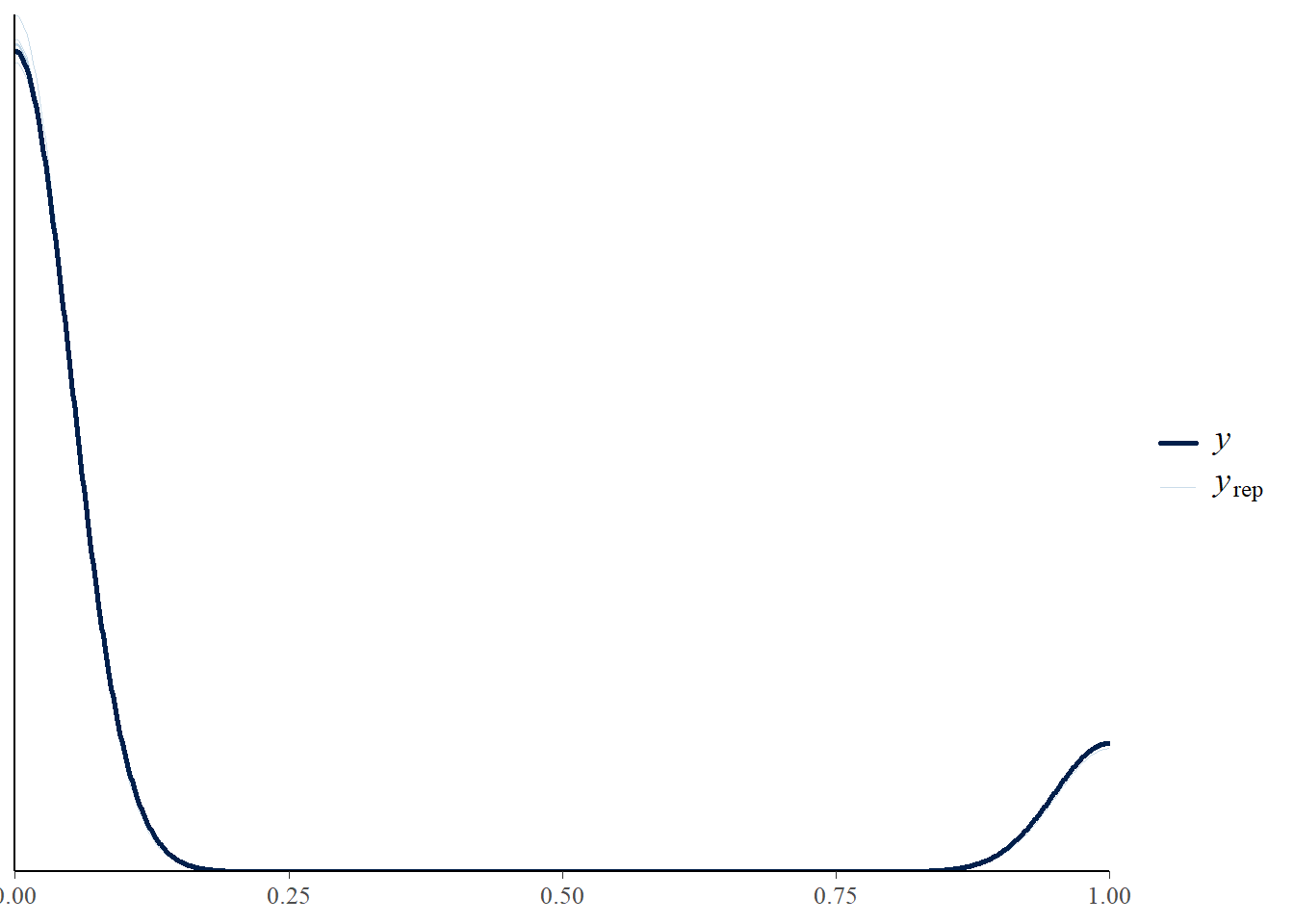
fit1 <- brm(
PM_model+
monitoring_model +
offloading_model +
set_rescor(F),
prior = priors,
sample_prior = "yes",
data = stress_int_red,
chains = 4, cores = 4,
iter = 2000,
warmup = 1000
)